DataBlock and Dataloaders in Fastai
DataBlock and DataLoader are Python Classes in the fastai library for data processing. They provide many useful methods to facilitate the handling of data.
In this post I show how DataLoaders and DataBlocks can be used by building a simple image classifier.
What are DataLoader?
DataLoader are extensions of Pytorch’s DataLoader Class but with more functionality and flexibility. They help you to investigate, clean, change and prepare you data before, during and after building your deep learning model.
You always need a DataLoader to build your fastai model.
DataLoader can be build in two different ways: 1️⃣ as its own class: then you need to define a DataSet class before with all relevant information about the data — the DataSet will become a parameter in the DataLoader class or 2️⃣ as a subclass of the DataBlock: then you only need the file path to your data — all other information about your data are stored in the DataBlock:
1️⃣ class
DataLoaderDataLoader(dataset=None, bs=None, num_workers=0, pin_memory=False, timeout=0, batch_size=None, shuffle=False, drop_last=False, indexed=None, n=None, device=None, persistent_workers=False, wif=None, before_iter=None, after_item=None, before_batch=None, after_batch=None, after_iter=None, create_batches=None, create_item=None, create_batch=None, retain=None, get_idxs=None, sample=None, shuffle_fn=None, do_batch=None)
2️⃣ class
DataBlock.dataloadersDataLoader(source, path=’.’, verbose=False, bs=64, num_workers=None, do_setup=True, pin_memory=False, timeout=0, batch_size=None, shuffle=False, drop_last=False, indexed=None, n=None, device=None, persistent_workers=False, wif=None, before_iter=None, after_item=None, before_batch=None, after_batch=None, after_iter=None, create_batches=None, create_item=None, create_batch=None, retain=None, get_idxs=None, sample=None, shuffle_fn=None, do_batch=None)
There are a lot of arguments 👆🏼 in the DataLoader class, but in most cases you only will need a few. In fact only on is necessary: the path to your data. You can either chose 1️⃣ and define this within a DataSet (another useful class provided by the fastai library which I do not cover in this article) or 2️⃣ simply by building your DataLoader as a subclass of the DataBlock and including source="path_to_Dataset" in your DataLoader— and even this can be be omitted if you define your dateset within the DataBlock class. I will use the latter approach in the following coding example. But let’s first get an idea about whatDataBlocks👇🏻 are.
What are Datablocks?
DataBlocks are blueprints on how to assemble data. Think of them as a pipeline about how to manage your entire dataflow.
class
DataBlockDataBlock(blocks=None, dl_type=None, getters=None, n_inp=None, item_tfms=None, batch_tfms=None, get_items=None, splitter=None, get_y=None, get_x=None)
☝🏻 Although the DataBlock has less paramaters and methods, it requires more arguments to be set. At least the DataBlock needs to know the following three arguments:
- what type of data (here:
blocks) - how are the features and labels defined (here:
get_itemsandget_y) - the validation set (
splitter)
Why do we need DataLoader and DataBlocks?
You might heard that Data Scientists, Data Engineers, Data Analysts, etc. spend most of their time with data munging, i.e.: getting the data, preparing the data, cleaning the data, etc. Depending on the specific model this data preprocessing part can take up to 90% of the whole workflow. This is were DataLoader and DataBlock come into play: they let us build a general, adjustable pipeline to manipulate our data without changing the raw data.
More data processing functionalities therefore means having more time for building and testing the model.
Building the DataLoader for an Ugly-Cat-Identifier
To see what we could do with a DataLoader let’s build something similiar to the Cat Identifier in the fastai Lesson 1 Course: a simple binary image classifier which identifies not-so-cute cats , among pretty cats — I call it the Ugly-Cat-Identifier (🙀🔍), i.e. a model (or maybe even later an app or website) that tells you if your cat is ugly (according to a basic Internet Image Search) or cute. With the help of fastai this can be done in a few lines of code. These are the basic steps:
1️⃣ Import Libraries → 2️⃣ Download/Source your data → 3️⃣ DataBlock → 4️⃣ DataLoader → 5️⃣ Data Munging → ... 🚀 Build Model→6️⃣ Reclassify Images
I am here not focussing on model building but I want to demonstrate a useful scenario for using DataLoaders: deleting and/or declassifying images within your Notebook and for this we need to build a basic image classifier model. If you are interested you can follow this code on my Github Repository where I provide Notebook and corresponding PDF to replicate the steps.
1. Import Libraries
Like always we need to import the relevant Python Libraries. For this small example we only need to import the fastbook library. I assume you have fastai installed. If not you will find all relevant information here.
To download our images I use the Python libraryDuckDuckGoImages which works surprisingly well. You can install it via pip directly from your Jupyter or Google Colab Notebook:
! pip install DuckDuckGoImagesand import it together with the fastai libraries:
from fastbook import *from fastai.vision.widgets import *import DuckDuckGoImages as ddg
2. Download Images
I created a parent folder for the images with two folders for every cat image category:..
├── /downloads
│ ├── /ugly_cats
│ └── /cute_cats
└── .ipyth or .py (your main Python file or Notebook from where you run your code)
and download the images with the help of DuckDuckGo Image Search:
ddg.download('pretty cats', max_urls=400, folder="downloads/cats/prettycats")
ddg.download('ugly cats', max_urls=400, folder="downloads/cats/uglycats")I decided to use the search terms pretty cats and ugly cats as a placeholder for cute or ugly cat images (other search terms might have been more useful). For this demonstration I limit the maximum search results to 400 by setting the max_url parameter (you can also set it to “none” which does not limit your search result):
At this point, you should check your downloaded images manually and delete any images you are not satisfied with (although fastai has a class called ImagesCleaner() which does exactly this within your Notebook, but I found it faster and more intuitive to do it by myself).
3. Build DataBlock
As mentioned above we need at least four arguments to setup our data pipeline. I will set the file path to the images in the DataLoader. But first I define the following parameters in the DataBlock:
cats = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128)
)The blocks parameter tells fastai that the datatype are images and its a categorization problem (instead of e.g. a regression problem). The get_items and get_y tells fastai how the features (images) and labels (in our case the name of the folders) are defined. In the splitterargument I chose a training-to-validation split of 80 : 20 and set a random seed number for reproducibility of the results. I also resized the images to 128px which is another useful method: usually when you sample images by yourself you probably will have different image sizes, wheras Neural Networks require all input images of the same size.
As a reminder, this image correction will be stored only in the DataBlock argument — the downloaded images will not be changed.
This is actually a good example about the usefulness of DataLoaders: not even that we dont have to resize every image by ourself, we can build our model first with a smaller pixel size and later (when we want to improve the model) use a higher pixel size. And again: this is all done with 1 parameter in the DataBlock — none of the original images will be touched.
4. Build DataLoader
Finally we need to build the DataLoader on top of our newly created DataBlock:
dls = cats.dataloaders(source = "downloads/cats")The DataLoader has all the information of our Data Pipeline and will be itself a parameter for our model.
5. Investigate, Clean, Change the Data
This is the place where DataLoader and DataBlocks become very useful. We can for example investigate our images in the training set with a simple one-liner:
dls.train.show_batch(max_n=6, nrows=1)
… or in the validation set:
dls.valid.show_batch(max_n=6, nrows=1)
Another useful function you will like is the verify_images() which iterates over all your images and checks for broken image files which you then can unlink from your DataBlock. (check out the detailed code here or on my Notebook)
We can furthermore do all kind of data augmentation to increase the total pool of images for our model to facilitate learning, resize the images, investigate images, etc.:
- convert to black-white images:
blocks=(ImageBlock(cls=PILImageBW), CategoryBlock) - resize images to 250x250px:
item_tfms=Resize(250) - get a detailed list of all your images in your training or validation set:
dls.train.datasetordls.valid.dataset
In case you run into trouble by setting up your data (which you usually will find out when you try to train the model and then get an error — typical examples might be that you forgot to resize all images) you might find cats.summary("downloads/cats") useful. It gives you a summary of all the steps in your data pipeline.
6️⃣ Reclassify Images
To use this very useful functionality of fastai we need to build a model for learning to classify images in our two categories. I am not going into much details here but in fastai it is simple two-liner:
# LEARN PRETRAINED MODEL WITH OUR IMAGES
learn = cc_learner(dls=dls, arch=resnet18, metrics=accuracy)
learn.fit_one_cycle(2)If we also want to see how good the models learning result is, we can use this code:
# DISPLAY CLASSIFICATION RESULT
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()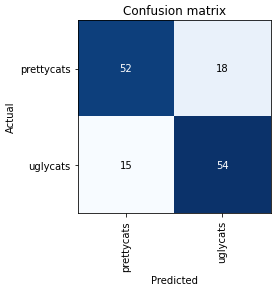
So we have 15+18=33 images which are not correctly classified. We can now reclassify and/or delete images within our Notebook by running:
cleaner = ImageClassifierCleaner(learn)
cleaner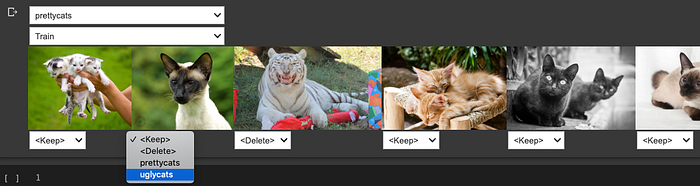
We can use this to go through every image within our two categories prettycats and uglycats and chose different categories or delete images.
In the above example I found the second image should be categorized as uglycats and the third picture contains a tiger, so I marked it for deleting.
To finally delete these images we need to run this code:
# DELETE MARKED IMAGESfor category in dls.vocab: for idx in cleaner.delete(): try: cleaner.fns[idx].unlink() except: pass cleaner.delete
And to finally change the categories (i.e.: images will be moved from /uglycats to /prettycats folder vice versa)
# UNCATEGORIZE MARKED IMAGESfor category in dls.vocab: for idx,category in cleaner.change(): try: shutil.move(str(cleaner.fns[idx]), PATH_TO_DATA+"/"+category) except: pass
Summary
This was a quick walk-thru through fastai’s DataLoader and DataBlock classes: I showed — by building a simple image classifier — how and why to use them. With a few lines of code you are able to download images from the internet and build a workable Deep Learning Image Classifier. Feel free to check out the code on Github …
Happy Coding!
👨🏻💻 Code on Github
- My corresponding Github Repository to this Medium article.
📚 References
- Fast.Ai DataLoader Documentation
- Fast.Ai DataBlock Documentation
- Howard, J. & Gugger, S. (2020) Deep Learning for Coders with fastai and PyTorch. O’Reilly, Sebastopol.
(Alternatively you can check out the corresponding website Practical Deep Learning for Coders which contains almost the same information like in the book 😉)
